I’ve been hitting the Ai research pretty hard the last week, and this setup seems to be working well, so I’m passing it along to you guys.
Heavy Duty AI
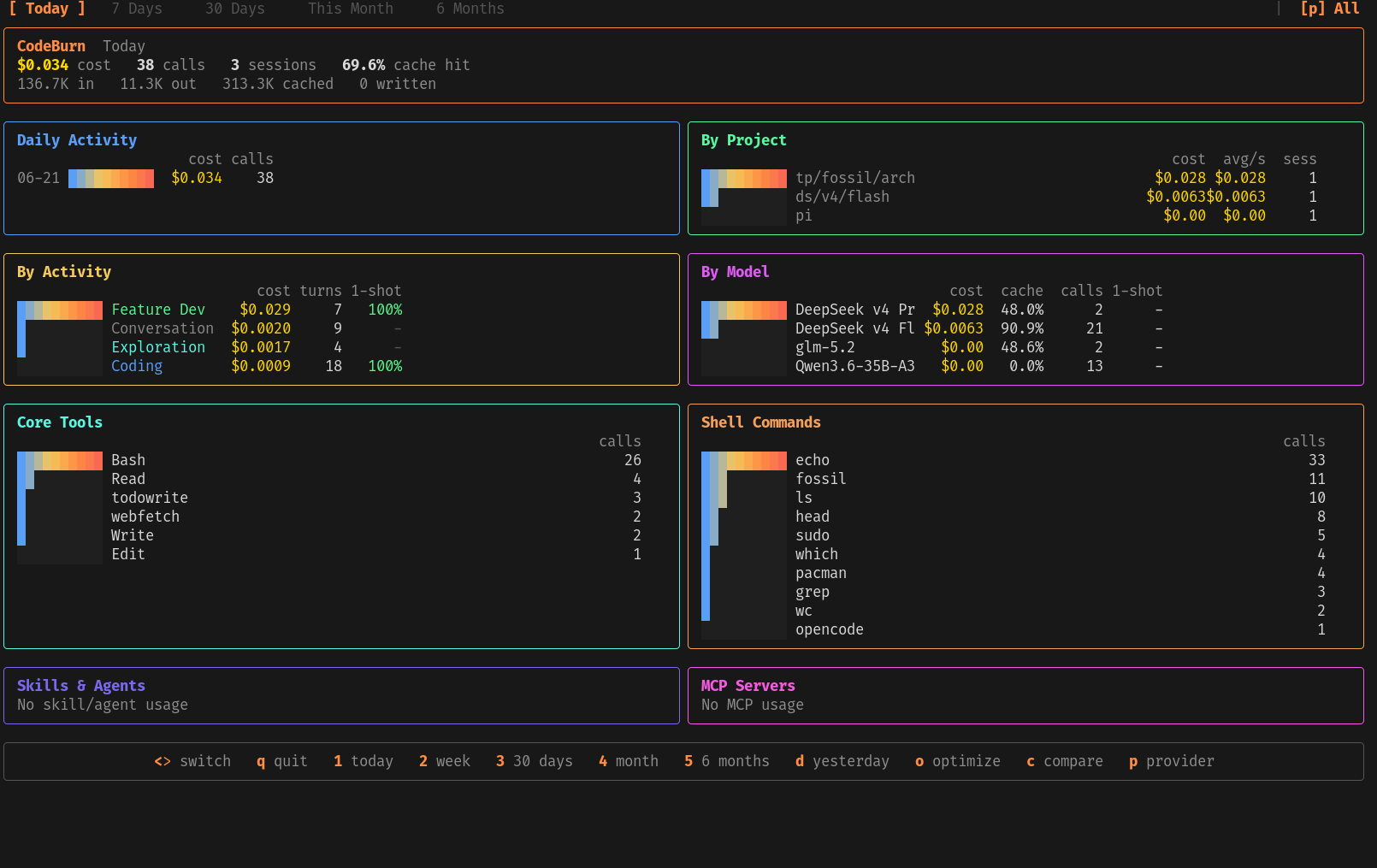
For serious work I use https://opencode.ai/
Opencode is set up to use GLM5.2 ($4.10 USD per million output tokens) in ‘plan mode’ and deepseek-v2-flash (0.20 per million output tokens) in ‘build mode’.
This way I get the latest Open AI for planning and good old reliable and cheap Deepseek-V4-Flash to build the plan.
I have the following in the project AGENTS.md tho GLM-5.2 created other files as well when it read this.
## Multi-Agent Workflow
- Plan mode uses GLM-5.2 for analysis; writes plans in structured markdown
- Build mode uses DeepSeek-V4-Flash for implementation; reads plan output as instructions
- Plans should use numbered steps, explicit file paths, and expected outcomes
Local AI
For PC Admin, designing electronics and simple coding I use https://pi.dev/
Pi is great, but unlike Opencode it comes bare-bones, no safeguards, so research that before using it outside a sandbox.
After a LOT of experimentation with at least 10 different local AI models, I’ve gone with one which I downloaded from https://huggingface.co/ and converted into a Ollama model
Qwen3.6-35B-A3B-Q8_0.gguf at 35194 MB in size
On this PC: Ryzen5500/64GB DDR4 and a single RTX3060 GPU, I’m getting 18.81 tokens/s which is amazing and very usable.
Why a 8 bit Quant at 35MB image size ?
Because it’s the most detailed Image I can run on my hardware, with one or even two RTX3060’s.
Now AI’s will tell you that smaller Quants than 8 ‘only lack a few minor details, that humans can’t perceive’ but I find this is a lie in my experience.
In my case the largest Quant has a LOT more information about details that are very important to me when doing PC Admin, or designing electronics or even simple coding, the areas where I find a local agent incredibly useful.
That’s all for now.