Another demo, this LLM image is 38GB in size and speed is quite reasonable, not too slow and not too fast!
[tp@nixos:~]$ ollama run llama2-uncensored:70b --verbose
>>> will china become the leading tech centre in the world ?
While China has made significant strides in the technology industry and is certainly a major
player, it's difficult to say with certainty whether they will become the leading tech center in
the world. There are many other countries and regions also making significant investments in
technology, and competition for leadership in this field is intense. Additionally, factors such as
political stability, innovation culture, education systems, and access to capital can all impact a
country's ability to maintain or improve its position in the tech industry.
total duration: 1m20.465920703s
load duration: 7.170557ms
prompt eval count: 35 token(s)
prompt eval duration: 2.642395277s
prompt eval rate: 13.25 tokens/s
eval count: 107 token(s)
eval duration: 1m17.815680532s
eval rate: 1.38 tokens/s
The new AI server has worked out perfectly! I’m finding qwen3:32b (20GB image) writes slightly faster than I can read, which is perfect when it’s advising me on software design strategies like below, so I’m the one struggling to keep up for a change.
You're already using **XSLT 1.0** to transform SVD (CMSIS-SVD) files into structured data. This
is a great approach to extract register names, bitfields, and base addresses. Below is a plan to
integrate this into your **Mecrisp LSP** for autocompletion and diagnostics in Neovim.
---
### **1. Workflow Overview**
1. **Parse SVD with XSLT**:
- Transform the SVD XML into a structured format (e.g., JSON or CSV) containing:
- Register names, base addresses, and offsets.
- Bitfield names, bit positions, and masks.
2. **Load Data in Python**:
- Parse the generated JSON/CSV in your `mecrisp_lsp.py` to build a symbol table.
3. **Integrate into LSP**:
- Use the symbol table for:
- **Autocompletion** (register names, bitfield names).
- **Diagnostics** (invalid register access, bitfield out-of-range).
---
It’s just staggering what this AI knows. This is a serious design tool in my opinion, and if it was any faster it would be wasted money for the work I do because I couldn’t keep up.
I now declare the AI server finished and a success. NixOS is completed, everything works perfectly including sound and video. The new PC case is quite nice, I’ll see if I can organise some pics of the finished unit showing the internals.
Now onto the new Freebsd powered NAS so I can access all my old data and start updating my website at Sourceforge again.
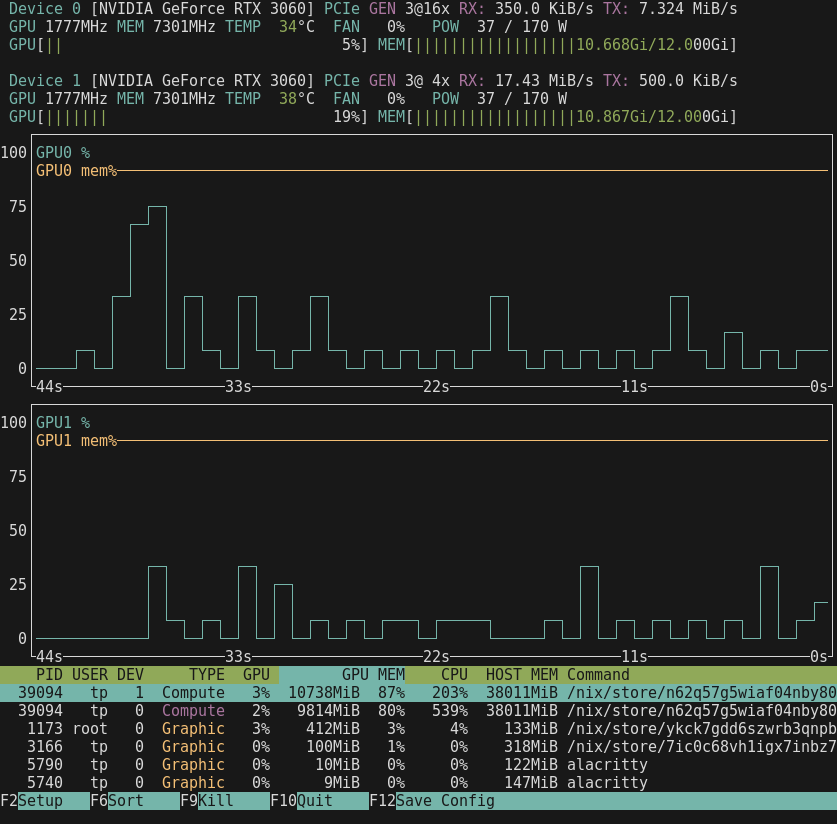
I’ve had nothing but trouble trying to get CUDA running on my machine today under NixOS.
I seem to be continually bumping up against CUDA error: no kernel image is available for execution on the device in ollama. It loads fine in CPU mode, but crashes out with that error when it tries to push layers to the GPU.
Card is detected fine, and nvidia-smi reports Driver Version: 570.153.02 and CUDA Version: 12.8 - exactly the same as your screenshots earlier in the thread. I feel as if I’m missing something really obvious. I’m running kernel 6.12.39 which came with NixOS installed earlier today. Did you need to install kernel headers or anything like that?
That’s interesting - NixOS has installed 6.12 for me on an install which I only did at lunch time today. I wonder if it’s something daft like the latest nvidia drivers and CUDA toolkit don’t like a kernel that old.
I’ll do a quick kernel upgrade now and will see how that goes. Otherwise I’ll send my config through. It’s definitely detecting the card (shown in ollama logs + nvtop + nvidia-smi, etc.) but just crashes when it tries to do any actual work. Go go gadget kernel upgrade.
Not in a VM. I flattened the $500 build (Debian) from the other thread and decided to leap both feet first into NixOS.
I’m now running 6.15.7. I still bump into Error: model runner has unexpectedly stopped, this may be due to resource limitations or an internal error, check ollama server logs for details when trying to run anything with Ollama. Brief snip from journalctl:
Jul 23 17:57:29 ai ollama[1273]: load_tensors: offloading 34 repeating layers to GPU
Jul 23 17:57:29 ai ollama[1273]: load_tensors: offloaded 34/49 layers to GPU
Jul 23 17:57:29 ai ollama[1273]: load_tensors: CUDA0 model buffer size = 5321.63 MiB
Jul 23 17:57:29 ai ollama[1273]: load_tensors: CPU_Mapped model buffer size = 3244.41 MiB
Jul 23 17:57:29 ai ollama[1273]: llama_context: constructing llama_context
Jul 23 17:57:29 ai ollama[1273]: llama_context: n_seq_max = 1
Jul 23 17:57:29 ai ollama[1273]: llama_context: n_ctx = 4096
Jul 23 17:57:29 ai ollama[1273]: llama_context: n_ctx_per_seq = 4096
Jul 23 17:57:29 ai ollama[1273]: llama_context: n_batch = 512
Jul 23 17:57:29 ai ollama[1273]: llama_context: n_ubatch = 512
Jul 23 17:57:29 ai ollama[1273]: llama_context: causal_attn = 1
Jul 23 17:57:29 ai ollama[1273]: llama_context: flash_attn = 0
Jul 23 17:57:29 ai ollama[1273]: llama_context: freq_base = 1000000.0
Jul 23 17:57:29 ai ollama[1273]: llama_context: freq_scale = 1
Jul 23 17:57:29 ai ollama[1273]: llama_context: n_ctx_per_seq (4096) < n_ctx_train (131072) – the full capacity of the model will not be utilized
Jul 23 17:57:29 ai ollama[1273]: llama_context: CPU output buffer size = 0.60 MiB
Jul 23 17:57:29 ai ollama[1273]: llama_kv_cache_unified: kv_size = 4096, type_k = ‘f16’, type_v = ‘f16’, n_layer = 48, can_shift = 1, padding = 32
Jul 23 17:57:29 ai ollama[1273]: llama_kv_cache_unified: CUDA0 KV buffer size = 544.00 MiB
Jul 23 17:57:29 ai ollama[1273]: llama_kv_cache_unified: CPU KV buffer size = 224.00 MiB
Jul 23 17:57:29 ai ollama[1273]: llama_kv_cache_unified: KV self size = 768.00 MiB, K (f16): 384.00 MiB, V (f16): 384.00 MiB
Jul 23 17:57:29 ai ollama[1273]: llama_context: CUDA0 compute buffer size = 926.08 MiB
Jul 23 17:57:29 ai ollama[1273]: llama_context: CUDA_Host compute buffer size = 18.01 MiB
Jul 23 17:57:29 ai ollama[1273]: llama_context: graph nodes = 1782
Jul 23 17:57:29 ai ollama[1273]: llama_context: graph splits = 200 (with bs=512), 3 (with bs=1)
Jul 23 17:57:29 ai ollama[1273]: time=2025-07-23T17:57:29.873+10:00 level=INFO source=server.go:637 msg=“llama runner started in 5.77 seconds”
Jul 23 17:57:29 ai ollama[1273]: [GIN] 2025/07/23 - 17:57:29 | 200 | 6.202421733s | 127.0.0.1 | POST “/api/generate”
Jul 23 17:57:34 ai ollama[1273]: ggml_cuda_compute_forward: ADD failed
Jul 23 17:57:34 ai ollama[1273]: CUDA error: no kernel image is available for execution on the device
Jul 23 17:57:34 ai ollama[1273]: current device: 0, in function ggml_cuda_compute_forward at /build/source/ml/backend/ggml/ggml/src/ggml-cuda/ggml-cuda.cu:2366
Jul 23 17:57:34 ai ollama[1273]: err
Jul 23 17:57:34 ai ollama[1273]: /build/source/ml/backend/ggml/ggml/src/ggml-cuda/ggml-cuda.cu:76: CUDA error
Jul 23 17:57:35 ai ollama[1273]: SIGSEGV: segmentation violation
configuration.nix is below. I think the only think I’m doing really differently is that I’m querying ollama via the API rather than running it on the CLI. Have xxxed out anything relating to my username or the LUKS encryption. There’s a few commented out lines where I tried the datacenter drivers to try and see if the Tesla card played nicer under those.:
# Edit this configuration file to define what should be installed on
# your system. Help is available in the configuration.nix(5) man page
# and in the NixOS manual (accessible by running ‘nixos-help’).
{ config, pkgs, ... }:
{
imports =
[ # Include the results of the hardware scan.
./hardware-configuration.nix
];
# Bootloader.
boot.loader.systemd-boot.enable = true;
boot.loader.efi.canTouchEfiVariables = true;
#latest kernel
boot.kernelPackages = pkgs.linuxPackages_latest;
boot.initrd.luks.devices."luks-xxxxxxxxxxx”.device = "/dev/disk/by-uuid/xxxxxxxxxx";
networking.hostName = "xxxxx"; # Define your hostname.
# networking.wireless.enable = true; # Enables wireless support via wpa_supplicant.
# Configure network proxy if necessary
# networking.proxy.default = "http://user:password@proxy:port/";
# networking.proxy.noProxy = "127.0.0.1,localhost,internal.domain";
# Enable networking
networking.networkmanager.enable = true;
# Set your time zone.
time.timeZone = "Australia/Brisbane";
# Select internationalisation properties.
i18n.defaultLocale = "en_AU.UTF-8";
i18n.extraLocaleSettings = {
LC_ADDRESS = "en_AU.UTF-8";
LC_IDENTIFICATION = "en_AU.UTF-8";
LC_MEASUREMENT = "en_AU.UTF-8";
LC_MONETARY = "en_AU.UTF-8";
LC_NAME = "en_AU.UTF-8";
LC_NUMERIC = "en_AU.UTF-8";
LC_PAPER = "en_AU.UTF-8";
LC_TELEPHONE = "en_AU.UTF-8";
LC_TIME = "en_AU.UTF-8";
};
nixpkgs.config.allowUnfree = true;
hardware.graphics.enable = true;
hardware.nvidia.open = false;
hardware.nvidia.package = config.boot.kernelPackages.nvidiaPackages.stable;
# hardware.nvidia.datacenter.enable = true;
# nixpkgs.config.nvidia.acceptLicense = true;
# Configure keymap in X11
services.xserver.xkb = {
layout = "au";
variant = "";
};
# Define a user account. Don't forget to set a password with ‘passwd’.
users.users.xxxxxxxxxx = {
isNormalUser = true;
description = “xxxxxxxxxx”;
extraGroups = [ "networkmanager" "wheel" ];
packages = with pkgs; [];
};
# List packages installed in system profile. To search, run:
# $ nix search wget
environment.systemPackages = with pkgs; [
# vim # Do not forget to add an editor to edit configuration.nix! The Nano editor is also installed by default.
# wget
ollama
nvtopPackages.nvidia
btop
# cudatoolkit
];
# Some programs need SUID wrappers, can be configured further or are
# started in user sessions.
# programs.mtr.enable = true;
# programs.gnupg.agent = {
# enable = true;
# enableSSHSupport = true;
# };
# List services that you want to enable:
# Enable the OpenSSH daemon.
services.openssh.enable = true;
services.xserver.videoDrivers = [ "nvidia" ];
services.ollama = {
enable = true;
acceleration = "cuda";
openFirewall = true;
host = "[::]";
};
# Open ports in the firewall.
# networking.firewall.allowedTCPPorts = [ ... ];
# networking.firewall.allowedUDPPorts = [ ... ];
# Or disable the firewall altogether.
# networking.firewall.enable = false;
# This value determines the NixOS release from which the default
# settings for stateful data, like file locations and database versions
# on your system were taken. It‘s perfectly fine and recommended to leave
# this value at the release version of the first install of this system.
# Before changing this value read the documentation for this option
# (e.g. man configuration.nix or on https://nixos.org/nixos/options.html).
system.stateVersion = "25.05"; # Did you read the comment?
}
I’d change ‘ollama’ to ‘ollama-cuda’ and rebuild. This will cause a lot of rebuilding.Failing that, I’d start again from scratch with ‘ollama-cuda’ because I had to as I’d borked something I couldn’t fix in the internals.
I doubt you need this “hardware.nvidia.package = config.boot.kernelPackages.nvidiaPackages.stable;”
Good catch. I’d swapped back and forth a few times. Back to the -cuda version now.
Agreed. I dropped back a few versions earlier in the day when trying to get the card to even detect and load drivers. Now commented out.
Still no success.
I wish! The last 3 of 4 hours have even finding which combination of drivers will even detect the card! Annoying that I’m now running up against something specifically ollama related.
I suspect a format and reinstall is in order, but at least I have a working config file that will detect the Tesla card now… . Thanks for your help. I’ll stick with the cuda version and force the latest kernel post-reinstall.
Same same on the 570 branch recommended by Nvidia for that card. Ollama crashes out at the same place, even locally with the API disabled. I added hardware.nvidia.package = config.boot.kernelPackages.nvidiaPackages.production;to force the 570 drivers as a last resort.
Will do a reinstall tomorrow. It should be a good test of how well the NixOS configuration goes. Thanks for your help - really appreciate it. (and sorry for the thread hijack!)
No worries. It’s the genuine Linux experience - 20 minutes to install, then a half day of compiling and recompiling and tearing one’s hair out to get the Nvidia card working…
I guess the big difference is that all my gear (except PSU) is brand new, and cost at least $1500.
As a retired tech, I’m just not attracted to old gear anymore and I replace all PC gear every 5 years whether it’s still working or not. If it’s still working I know it won’t be for long and when it breaks it will be on its timetable not mine, which I always find most inconvenient
The wise course would be to budget every week/fortnight so one has $5000 to spend on decent parts when the time arrives imho.
After examining my emotions of apprehension on the matter I realised that prior to 1994 I functioned perfectly fine without the Internet like most people, so why my strong feelings ?
Pre 1994 I had a huge collection of technical and data books for all my interests, but most of these are now gone, outdated. Heavy and expensive, they were replaced by on-line facilities signposted by Google.
No Internet meant no fast access to accurate information and ideas, or did it ?
With the completion of my new NixOS powered AI PC, I now have a fast and kick ass AI, mainly qwen3:32b which is an oracle of information without adverts or politics.
I then felt oddly calm knowing that the daily research and development of my many projects would continue unhindered even tho the Internet was currently non-functional.
So I turned on my always charged and ready Tecsun PL-30 radio and listened to a radio station in Byron as I worked on a LSP feeling oddly calm and un-hassled
(The Internet came back on a couple of hours later)
Was thinking of you today when I heard on the radio while driving that the whole lot was down! Glad it wasn’t a massive ongoing outage. Great outcome too that the local AI PC build is finished and covered your needs without the outage!
(PS: looked up the PL-30 - nice looking bit of kit! I haven’t exactly gone searching for that use case before, but I was pleasantly surprised to see that people are still making modern consumer radios that receive LW, have SSB, etc. Very cool.)
The whole lot of what exactly was down ? Starlink ? It wouldn’t have mattered really as the AI PC has really made that much difference in my case.
My plan was to eventually drop Starlink anyway in the long term and just have a minimum Aldi cellphone internet of about 20GB a month for facilities like this, and my IRC channel (Forth).
The PL-30 is really excellent, low noise, low power, most bands and USB with a li-po battery and clock. When I do drop Starlink, I’ll probably put up a long external antenna and listen to shortwave in the evenings.
I also have a internal TV yagi pointing at the tower on the caldera, thru a window and I’ll probably fire up the old mythTV again ( t has a couple of 3 channel digital TV cards in it) and start recording TV again. One can acquire GB of HD films in no time that way.