As previously mentioned I have been working on increasing the likelihood of HLB emails getting through. As we are all aware email is an ancient internet technology and if its protocols were proposed today that would be dismissed as too complicated and too insecure. Nevertheless we have it and mostly like it and would rather it than Facebook messenger.
Protocols such as dkim, spf and dmarc have been devised to increase the reliability and security of email. dmarc can give managers of email servers feedback about how successful their emails are at getting through to the intended recipients. Large companies such as Yahoo, Google and Microsoft will email admins dmarc reports with this information.
The raw XML dmarc reports are not hard to read but are designed for computer consumption. If you were to get hundreds of them it is hard to elicit the useful information in a concise format.
Parsing dmarc reports can help and the appropriately named parsedmarc app will do that for you. When combined with Elastic Search and Kubana in a docker container one can get graphical representations of the combined data. Unfortunately, I am not familiar with Kubana and ElasticSearch and struggled to get things going.
One recent option for understanding a topic is to use a RAG (retrieval-augmented generation) AI model. This is how perplexity works retrieving recent relevant documents from the web and integrating them with an LLM to produce an answer.
A variation on this is to specify the source documents. Google’s NotebookLM is one example and there are others which I have not used.
For GNLM I gave it the parsedmarc documentation, its docker file and a youtube and it went and did its stuff (Google login required ;-( ).
As you can see it creates output in a variety of formats such as a briefing doc, FAQ and study guide for students where it will create questions on the topic and provide them with the answers if they get stuck.
You can also generate a podcast and vodcast that run for about 10 to 15 minutes. These can be a little annoying but I learnt a couple more things about the topic that I had missed during my working through the source documents.
I will continue to play with it and see how it goes for my problems and my workflow. I can clearly see how it would be of great advantage in a workplace environment for a company’s documents and can see a role for it in many areas such as on-boarding new staff and disseminating new baseline information within the company.
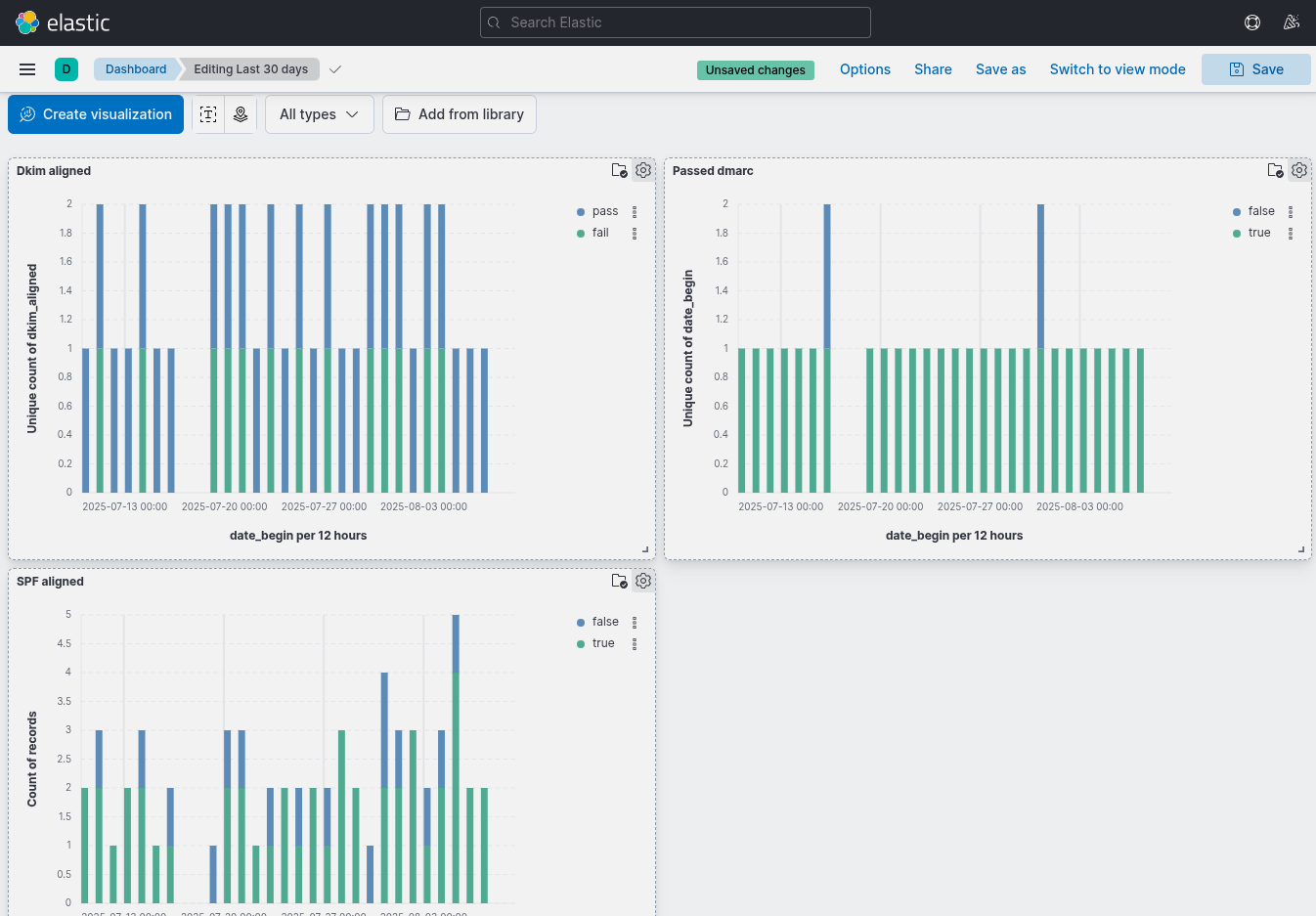
These graphs are not very sophisticated but are automatically generated when the dmarc emails come through. After reviewing these graphs I made some tweaks and hopefully the false and fails will exit stage left over the next 30 days.